什么是事务?什么是隔离级别?
数据库中使用了多少种锁?这些锁之间有什么关系?
数据库如何在并发度和各种并发问题中平衡?
事务与隔离级别
事务四要素
- 原子性(Atomicity):要么全部完成,要么全部不完成;
- 一致性(Consistency):一个事务单元需要提交之后才会被其他事务可见;
- 隔离性(Isolation):并发事务之间不会互相影响,设立了不同程度的隔离级别,通过适度的破坏一致性,得以提高性能;
- 持久性(Durability):事务提交后即持久化到磁盘不会丢失。
并发问题名词解释
以下表为例子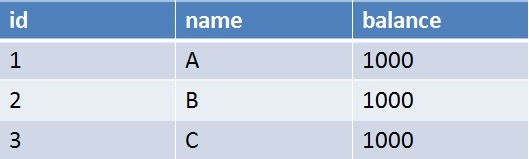
脏读 dirty read
没有提交的事务被其他事务读取到了,这叫做脏读。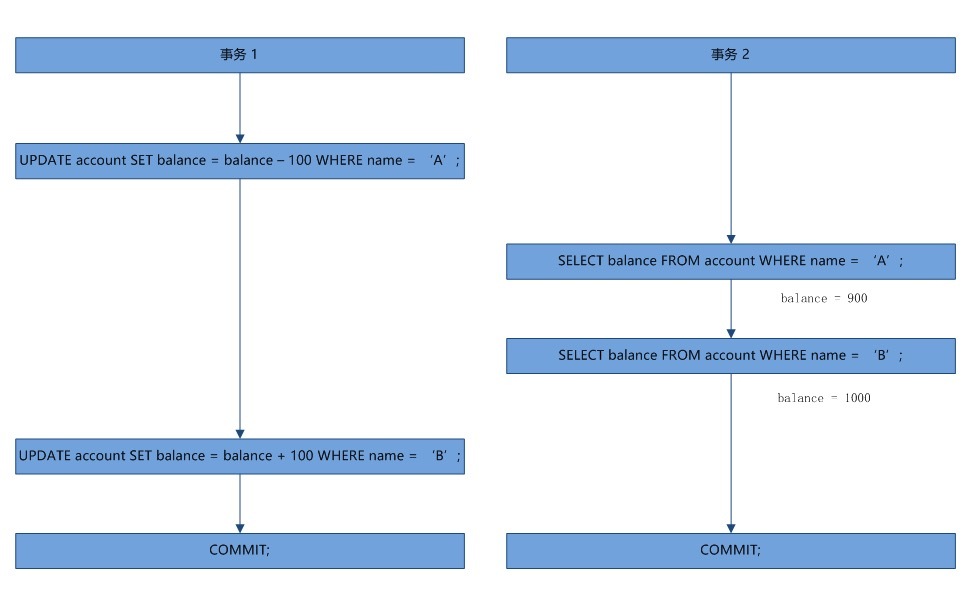
事务开始之前两个人各有1000元
事务一执行了转账操作,事务二统计两个人一共有多少钱。事务2的到的结果明显是错误的。
不可重复读 unrepeatable read
同一个事务对同一条记录读取两遍,两次读出来的结果不一样,称为不可重复读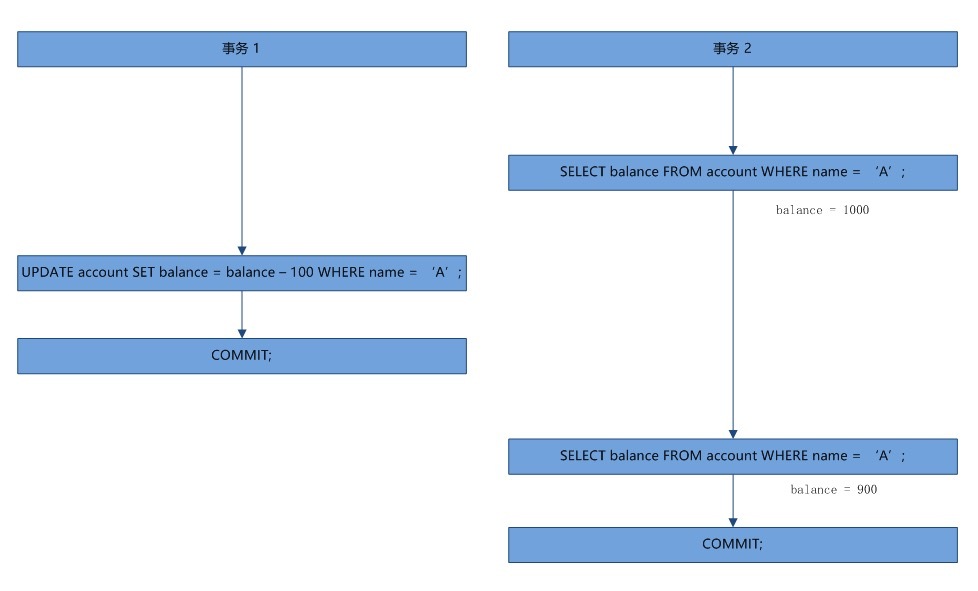
事务2中两次执行同一条SQL得到的结果却不同。不可重复读与脏读的区别在于,不可重复读读到的是其他事务已经提交的修改,而脏读是读到了其他事务还未提交的修改。
幻读 phantom read
同样的条件,第一次和第二次读出来的记录数不一样,称为幻读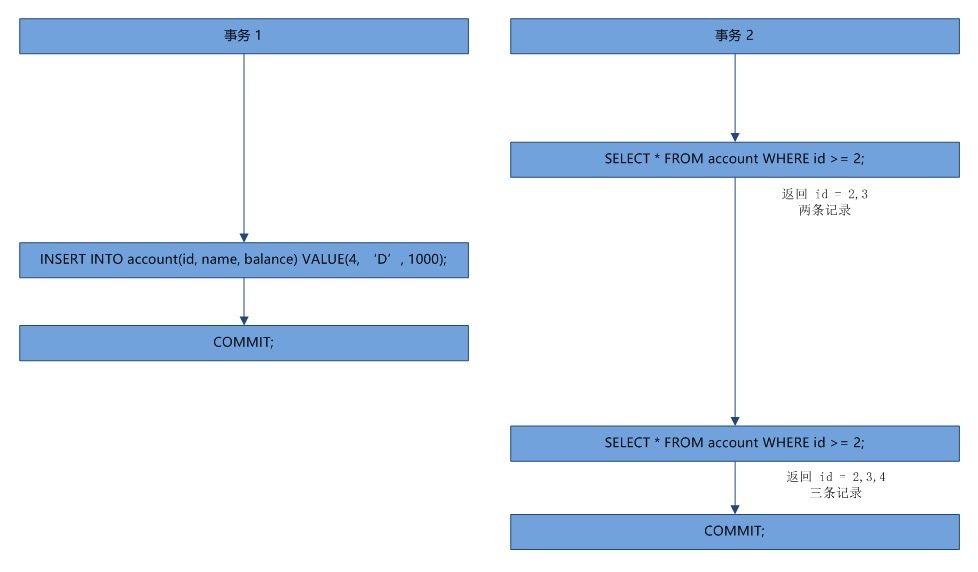
同样的条件,第一次和第二次读出来的记录集合不一样。不可重复读是因为其他事务进行了 UPDATE 操作,幻读是因为其他事务进行了 INSERT 或者 DELETE 操作。
事务 2 的两次查询,第一次查出 2 条记录,第二次却查出 3 条记录,多出来的这条记录,正如 phantom(幽灵,幻影,错觉) 的意思,就像幽灵一样。
丢失更新 lost update
两个事务都是写操作,某种情况下有些修改被提交后又被覆盖了,称为丢失更新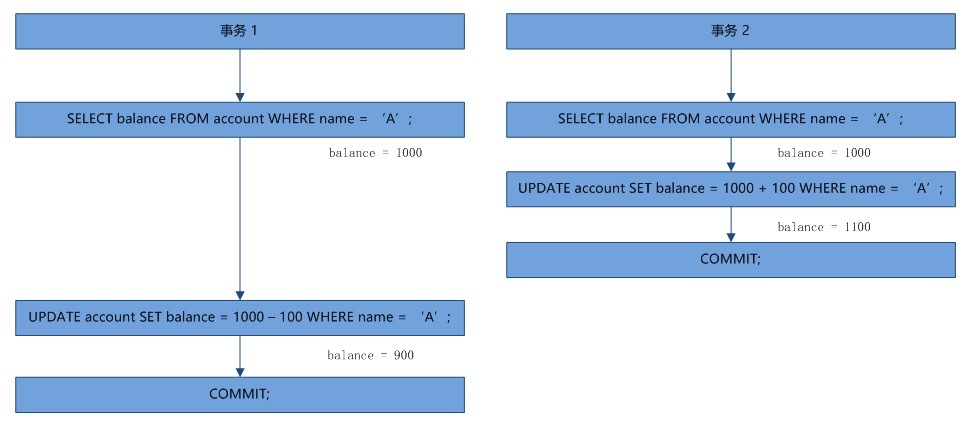
上图中事务2的提交覆盖了事务1的提交。
上图中事务1的回滚直接忽视了事务2的 UPDATE 操作
隔离级别
为了有效的保证数据一致性和数据库并发性能,便有了四种不同的数据库隔离级别
- 读未提交(Read Uncommitted):可以读取未提交的记录,会出现脏读,幻读,不可重复读,所有并发问题都可能遇到;
- 读已提交(Read Committed):事务中只能看到已提交的修改,不会出现脏读现象,但是会出现幻读,不可重复读;(大多数数据库的默认隔离级别都是 RC,但是 MySQL InnoDb 默认是 RR)
- 可重复读(Repeatable Read):MySQL InnoDb 默认的隔离级别,解决了不可重复读问题,但是任然存在幻读问题;(MySQL 的实现有差异,后面介绍)
- 序列化(Serializable):最高隔离级别,啥并发问题都没有。
针对这四种隔离级别,应该根据具体的业务来取舍,如果某个系统的业务里根本就不会出现重复读的场景,完全可以将数据库的隔离级别设置为 RC,这样可以最大程度的提高数据库的并发性。不同的隔离级别和可能发生的并发现象如下表: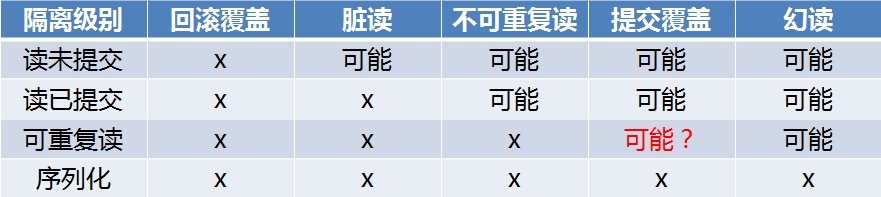
RR级别下会出现提交覆盖吗?答案文末揭晓。
隔离级别的实现
上面所说的都是事务和隔离级别的概念,是 SQL 标准中通用的概念,不同的数据库产品有不同的实现。
传统的隔离级别
传统的隔离级别是基于锁实现的,这种方式叫做 基于锁的并发控制(Lock-Based Concurrent Control,简写 LBCC)
通过对读写操作加不同的锁,以及对释放锁的时机进行不同的控制,就可以实现四种隔离级别。传统的锁有两种:读操作通常加共享锁(Share locks,S锁,又叫读锁),写操作加排它锁(Exclusive locks,X锁,又叫写锁);加了共享锁的记录,其他事务也可以读,但不能写;加了排它锁的记录,其他事务既不能读,也不能写。另外,对于锁的粒度,又分为行锁和表锁,行锁只锁某行记录,对其他行的操作不受影响,表锁会锁住整张表,所有对这个表的操作都受影响。
归纳起来,四种隔离级别的加锁策略如下:
- 读未提交(Read Uncommitted):事务读不阻塞其他事务读和写,事务写阻塞其他事务写但不阻塞读;通过对写操作加 “持续X锁”,对读操作不加锁 实现;
- 读已提交(Read Committed):事务读不会阻塞其他事务读和写,事务写会阻塞其他事务读和写;通过对写操作加 “持续X锁”,对读操作加 “临时S锁” 实现;不会出现脏读;
- 可重复读(Repeatable Read):事务读会阻塞其他事务事务写但不阻塞读,事务写会阻塞其他事务读和写;通过对写操作加 “持续X锁”,对读操作加 “持续S锁” 实现;
- 序列化(Serializable):为了解决幻读问题,行级锁做不到,需使用表级锁。
通过对锁的类型(读锁还是写锁),锁的粒度(行锁还是表锁),持有锁的时间(临时锁还是持续锁)合理的进行组合,就可以实现四种不同的隔离级别。这四种不同的加锁策略实际上又称为 封锁协议(Locking Protocol),所谓协议,就是说不论加锁还是释放锁都得按照特定的规则来。读未提交 的加锁策略又称为 一级封锁协议,后面的分别是二级,三级,序列化 的加锁策略又称为 四级封锁协议。
其中三级封锁协议在事务的过程中为写操作加持续 X 锁,为读操作加持续 S 锁,并且在事务结束时才对锁进行释放,像这种加锁和解锁明确的分成两个阶段我们把它称作 两段锁协议(2-phase locking,简称 2PL)。在两段锁协议中规定,加锁阶段只允许加锁,不允许解锁;而解锁阶段只允许解锁,不允许加锁。这种方式虽然无法避免死锁,但是两段锁协议可以保证事务的并发调度是串行化的(关于串行化是一个非常重要的概念,尤其是在数据恢复和备份的时候)。在两段锁协议中,还有一种特殊的形式,叫 一次封锁,意思是指在事务开始的时候,将事务可能遇到的数据全部一次锁住,再在事务结束时全部一次释放,这种方式可以有效的避免死锁发生。
MySQL的隔离级别
虽然数据库的四种隔离级别通过 LBCC 技术都可以实现,但是它最大的问题是它只实现了并发的读读,对于并发的读写还是冲突的,写时不能读,读时不能写,当读写操作都很频繁时,数据库的并发性将大大降低,针对这种场景,MVCC 技术应运而生。MVCC 的全称叫做 Multi-Version Concurrent Control(多版本并发控制)。
InnoDb 会为每一行记录增加几个隐含的“辅助字段”,(实际上是 3 个字段:一个隐式的 ID 字段,一个事务 ID,还有一个回滚指针),事务在写一条记录时会将其拷贝一份生成这条记录的一个原始拷贝,写操作同样还是会对原记录加锁,但是读操作会读取未加锁的新记录,这就保证了读写并行。要注意的是,生成的新版本其实就是 undo log,它也是实现事务回滚的关键技术。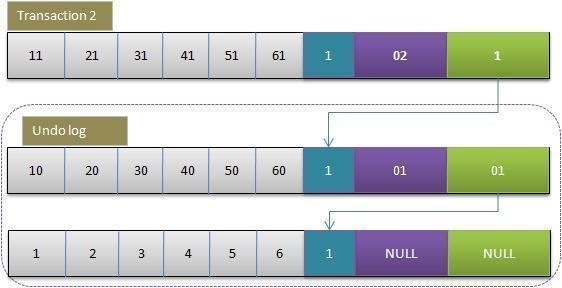
在 read uncommit 隔离级别下,每次都是读取最新版本的数据行,所以不能用 MVCC 的多版本,而 serializable 隔离级别每次读取操作都会为记录加上读锁,也和 MVCC 不兼容,所以只有 RC 和 RR 这两个隔离级别才有 MVCC。
RR 和 RC 隔离级别都实现了 MVCC 来满足读写并行,但是读的实现方式是不一样的:RC 总是读取记录的最新版本,如果该记录被锁住,则读取该记录最新的一次快照,而 RR 是读取该记录事务开始时的那个版本。虽然这两种读取方式不一样,但是它们读取的都是快照数据,并不会被写操作阻塞,所以这种读操作称为 快照读(Snapshot Read),有时候也叫做 非阻塞读(Nonlocking Read)
除了 快照读 ,MySQL 还提供了另一种读取方式:当前读(Current Read),有时候又叫做 加锁读(Locking Read) 或者 阻塞读(Blocking Read),这种读操作读的不再是数据的快照版本,而是数据的最新版本,并会对数据加锁,根据加锁的不同,又分成两类:
- SELECT … LOCK IN SHARE MODE:加 S 锁
- SELECT … FOR UPDATE:加 X 锁
- INSERT / UPDATE / DELETE:加 X 锁
当前读在 RR 和 RC 两种隔离级别下的实现也是不一样的:RC 只加记录锁,RR 除了加记录锁,还会加间隙锁,用于解决幻读问题。
不同隔离级别下InnoDB的读操作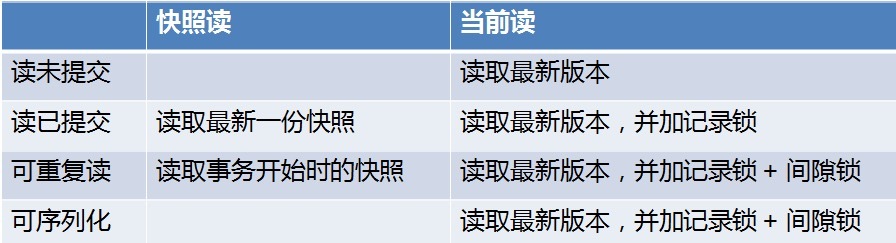
答案
MySQL 的实现和 ANSI-SQL 标准之间的差异,在标准的传统实现中,RR 隔离级别是使用持续的 X 锁和持续的 S 锁来实现的(参看下面的 “隔离级别的实现” 一节),由于是持续的 S 锁,所以避免了其他事务有写操作,也就不存在提交覆盖问题。但是 MySQL 在 RR 隔离级别下,普通的 SELECT 语句只是快照读,没有任何的加锁,和标准的 RR 是不一样的。如果要让 MySQL 在 RR 隔离级别下不发生提交覆盖,可以使用 SELECT … LOCK IN SHARE MODE 或者 SELECT … FOR UPDATE 。
常见锁类型
表锁 & 行锁
在 MySQL 中锁的种类有很多,但是最基本的还是表锁和行锁:表锁指的是对一整张表加锁,一般是 DDL 处理时使用,也可以自己在 SQL 中指定;而行锁指的是锁定某一行数据或某几行,或行和行之间的间隙。行锁的加锁方法比较复杂,但是由于只锁住有限的数据,对于其它数据不加限制,所以并发能力强,通常都是用行锁来处理并发事务。表锁由 MySQL 服务器实现,行锁由存储引擎实现,常见的就是 InnoDb,所以通常我们在讨论行锁时,隐含的一层意义就是数据库的存储引擎为 InnoDb ,而 MyISAM 存储引擎只能使用表锁。
表锁
表锁由 MySQL 服务器实现,所以无论你的存储引擎是什么,都可以使用。一般在执行 DDL 语句时,譬如 ALTER TABLE 就会对整个表进行加锁。在执行 SQL 语句时,也可以明确对某个表加锁,譬如下面的例子
1 | lock table products read; |
上面的 SQL 首先对 products 表加一个表锁,然后执行查询语句,最后释放表锁。
表锁可以细分成两种:读锁和写锁,如果是加写锁,则是 lock table products write 。
关于表锁,我们要了解它的加锁和解锁原则,要注意的是它使用的是 一次封锁 技术,也就是说,我们会在会话开始的地方使用 lock 命令将后面所有要用到的表加上锁,在锁释放之前,我们只能访问这些加锁的表,不能访问其他的表,最后通过 unlock tables 释放所有表锁。这样的好处是,不会发生死锁!所以我们在 MyISAM 存储引擎中,是不可能看到死锁场景的。对多个表加锁的例子如下:
1 | lock table products read, orders read; |
可以看到由于没有对 users 表加锁,在持有表锁的情况下是不能读取的,另外,由于加的是读锁,所以后面也不能对 orders 表进行更新。MySQL 表锁的加锁规则如下:
- 对于读锁
- 持有读锁的会话可以读表,但不能写表;
- 允许多个会话同时持有读锁;
- 其他会话就算没有给表加读锁,也是可以读表的,但是不能写表;
- 其他会话申请该表写锁时会阻塞,直到锁释放。
- 对于写锁
- 持有写锁的会话既可以读表,也可以写表;
- 只有持有写锁的会话才可以访问该表,其他会话访问该表会被阻塞,直到锁释放;
- 其他会话无论申请该表的读锁或写锁,都会阻塞,直到锁释放。
锁的释放规则如下:
- 使用 UNLOCK TABLES 语句可以显示释放表锁;
- 如果会话在持有表锁的情况下执行 LOCK TABLES 语句,将会释放该会话之前持有的锁;
- 如果会话在持有表锁的情况下执行 START TRANSACTION 或 BEGIN 开启一个事务,将会释放该会话之前持有的锁;
- 如果会话连接断开,将会释放该会话所有的锁。
行锁
表锁不仅实现和使用都很简单,而且占用的系统资源少,所以在很多存储引擎中使用,如 MyISAM、MEMORY、MERGE 等,MyISAM 存储引擎几乎完全依赖 MySQL 服务器提供的表锁机制,查询自动加表级读锁,更新自动加表级写锁,以此来解决可能的并发问题。但是表锁的粒度太粗,导致数据库的并发性能降低,为了提高数据库的并发能力,InnoDb 引入了行锁的概念。行锁和表锁对比如下:
- 表锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低;
- 行锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
行锁和表锁一样,也分成两种类型:读锁和写锁。常见的增删改(INSERT、DELETE、UPDATE)语句会自动对操作的数据行加写锁,查询的时候也可以明确指定锁的类型,SELECT … LOCK IN SHARE MODE 语句加的是读锁,SELECT … FOR UPDATE 语句加的是写锁。
行锁这个名字听起来像是这个锁加在某个数据行上,实际上这里要指出的是:在 MySQL 中,行锁是加在索引上的。
MySQL 加锁流程
当执行下面的 SQL 时(id 为 students 表的主键),我们要知道,InnoDb 存储引擎会在 id = 49 这个主键索引上加一把 X 锁。
1 | update students set score = 100 where id = 49; |
当执行下面的 SQL 时(name 为 students 表的二级索引),InnoDb 存储引擎会在 name = ‘Tom’ 这个索引上加一把 X 锁,同时会通过 name = ‘Tom’ 这个二级索引定位到 id = 49 这个主键索引,并在 id = 49 这个主键索引上加一把 X 锁。
1 | update students set score = 100 where name = 'Tom'; |
加锁过程如下图所示: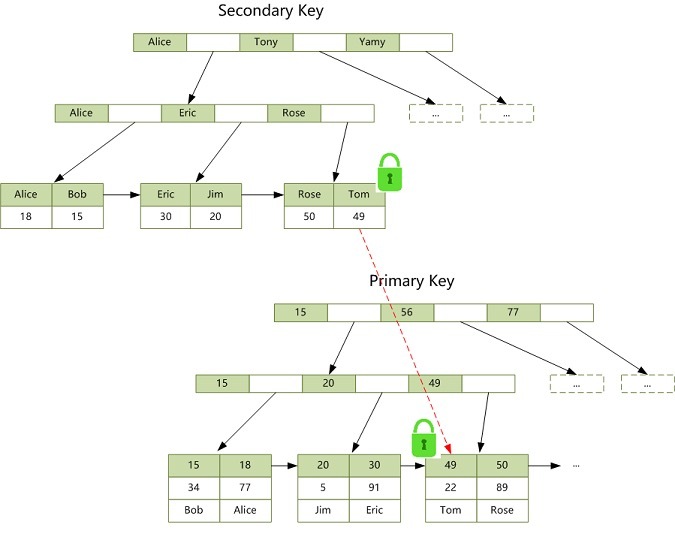
多条记录的加锁流程:
1 | update students set level = 3 where score >= 60; |
下图展示了当用户执行这条 SQL 时,MySQL Server 和 InnoDb 之间的执行流程: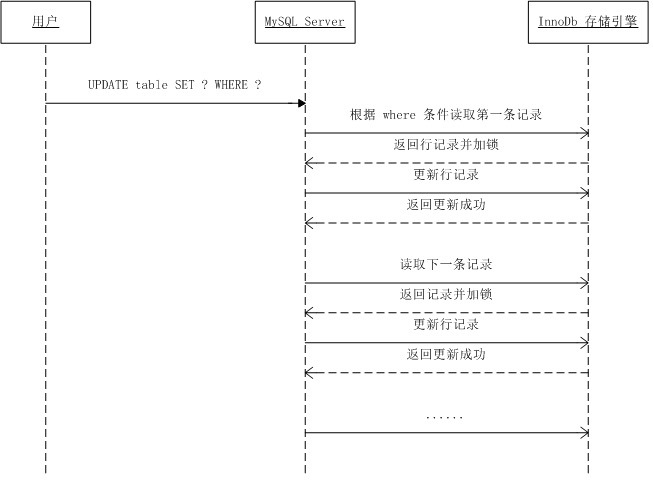
MySQL 在操作多条记录时 InnoDB 与 MySQL Server 的交互是一条一条进行的,加锁也是一条一条依次进行的,先对一条满足条件的记录加锁,返回给 MySQL Server,做一些 DML 操作,然后在读取下一条加锁,直至读取完毕。
行锁种类
根据锁的粒度可以把锁细分为表锁和行锁,行锁根据场景的不同又可以进一步细分,在 MySQL 的源码里,定义了四种类型的行锁,如下:
1 |
|
- LOCK_ORDINARY:也称为 Next-Key Lock,锁一条记录及其之前的间隙,这是 RR 隔离级别用的最多的锁,从名字也能看出来;
- LOCK_GAP:间隙锁,锁两个记录之间的 GAP,防止记录插入;
- LOCK_REC_NOT_GAP:只锁记录;
- LOCK_INSERT_INTENSION:插入意向 GAP 锁,插入记录时使用,是 LOCK_GAP 的一种特例。
读锁 & 写锁
MySQL 将锁分成两类:锁类型(lock_type)和锁模式(lock_mode)。锁类型就是上文中介绍的表锁和行锁两种类型,当然行锁还可以细分成记录锁和间隙锁等更细的类型,锁类型描述的锁的粒度,也可以说是把锁具体加在什么地方;而锁模式描述的是到底加的是什么锁,譬如读锁或写锁。锁模式通常是和锁类型结合使用的,锁模式在 MySQL 的源码中定义如下:
1 | /* Basic lock modes */ |
- LOCK_IS:读意向锁;
- LOCK_IX:写意向锁;
- LOCK_S:读锁;
- LOCK_X:写锁;
- LOCK_AUTO_INC:自增锁;
将锁分为读锁和写锁主要是为了提高读的并发,如果不区分读写锁,那么数据库将没办法并发读,并发性将大大降低。而 IS(读意向)、IX(写意向)只会应用在表锁上,方便表锁和行锁之间的冲突检测。LOCK_AUTO_INC 是一种特殊的表锁。下面依次进行介绍。
读写锁
读锁和写锁都是最基本的锁模式,它们的概念也比较容易理解。读锁,又称共享锁(Share locks,简称 S 锁),加了读锁的记录,所有的事务都可以读取,但是不能修改,并且可同时有多个事务对记录加读锁。写锁,又称排他锁(Exclusive locks,简称 X 锁),或独占锁,对记录加了排他锁之后,只有拥有该锁的事务可以读取和修改,其他事务都不可以读取和修改,并且同一时间只能有一个事务加写锁。(注意:这里说的读都是当前读,快照读是无需加锁的,记录上无论有没有锁,都可以快照读)
读写意向锁
表锁锁定了整张表,而行锁是锁定表中的某条记录,它们俩锁定的范围有交集,因此表锁和行锁之间是有冲突的。譬如某个表有 10000 条记录,其中有一条记录加了 X 锁,如果这个时候系统需要对该表加表锁,为了判断是否能加这个表锁,系统需要遍历表中的所有 10000 条记录,看看是不是某条记录被加锁,如果有锁,则不允许加表锁,显然这是很低效的一种方法,为了方便检测表锁和行锁的冲突,从而引入了意向锁。
意向锁为表级锁,也可分为读意向锁(IS 锁)和写意向锁(IX 锁)。当事务试图读或写某一条记录时,会先在表上加上意向锁,然后才在要操作的记录上加上读锁或写锁。这样判断表中是否有记录加锁就很简单了,只要看下表上是否有意向锁就行了。意向锁之间是不会产生冲突的,也不和 AUTO_INC 表锁冲突,它只会阻塞表级读锁或表级写锁,另外,意向锁也不会和行锁冲突,行锁只会和行锁冲突。
下面是各个表锁之间的兼容矩阵: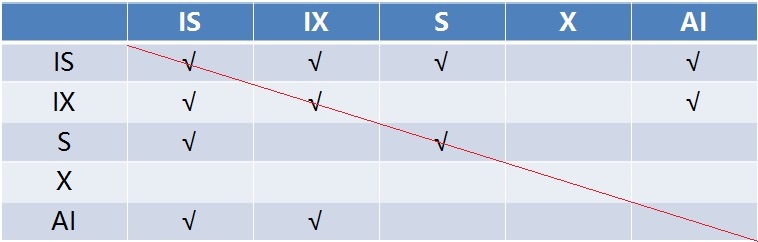
AUTO_INC 锁
AUTO_INC 锁又叫自增锁(一般简写成 AI 锁),它是一种特殊类型的表锁,当插入的表中有自增列(AUTO_INCREMENT)的时候可能会遇到。当插入表中有自增列时,数据库需要自动生成自增值,在生成之前,它会先为该表加 AUTO_INC 表锁,其他事务的插入操作阻塞,这样保证生成的自增值肯定是唯一的。AUTO_INC 锁具有如下特点:
- AUTO_INC 锁互不兼容,也就是说同一张表同时只允许有一个自增锁;
- 自增锁不遵循二段锁协议,它并不是事务结束时释放,而是在 INSERT 语句执行结束时释放,这样可以提高并发插入的性能。
- 自增值一旦分配了就会 +1,如果事务回滚,自增值也不会减回去,所以自增值可能会出现中断的情况。
显然,AUTO_INC 表锁会导致并发插入的效率降低,为了提高插入的并发性,MySQL 从 5.1.22 版本开始,引入了一种可选的轻量级锁(mutex)机制来代替 AUTO_INC 锁,我们可以通过参数 innodb_autoinc_lock_mode 控制分配自增值时的并发策略。参数 innodb_autoinc_lock_mode 可以取下列值:
innodb_autoinc_lock_mode = 0 (traditional lock mode)
- 使用传统的 AUTO_INC 表锁,并发性比较差。
innodb_autoinc_lock_mode = 1 (consecutive lock mode)
- MySQL 默认采用这种方式,是一种比较折中的方法。
- MySQL 将插入语句分成三类:
Simple inserts、Bulk inserts、Mixed-mode inserts。通过分析 INSERT 语句可以明确知道插入数量的叫做Simple inserts,譬如最经常使用的 INSERT INTO table VALUE(1,2) 或 INSERT INTO table VALUES(1,2), (3,4);通过分析 INSERT 语句无法确定插入数量的叫做 Bulk inserts,譬如 INSERT INTO table SELECT 或 LOAD DATA 等;还有一种是不确定是否需要分配自增值的,譬如 INSERT INTO table VALUES(1,’a’), (NULL,’b’), (5, ‘C’), (NULL, ‘d’) 或 INSERT … ON DUPLICATE KEY UPDATE,这种叫做Mixed-mode inserts。 - Bulk inserts 不能确定插入数使用表锁;Simple inserts 和 Mixed-mode inserts 使用轻量级锁 mutex,只锁住预分配自增值的过程,不锁整张表。Mixed-mode inserts 会直接分析语句,获得最坏情况下需要插入的数量,一次性分配足够的自增值,缺点是会分配过多,导致浪费和空洞。
- 这种模式的好处是既平衡了并发性,又能保证同一条 INSERT 语句分配的自增值是连续的。
innodb_autoinc_lock_mode = 2 (interleaved lock mode)
- 全部都用轻量级锁 mutex,并发性能最高,按顺序依次分配自增值,不会预分配。
- 缺点是不能保证同一条 INSERT 语句内的自增值是连续的,这样在复制(replication)时,如果 binlog_format 为 statement-based(基于语句的复制)就会存在问题,因为是来一个分配一个,同一条 INSERT 语句内获得的自增值可能不连续,主从数据集会出现数据不一致。所以在做数据库同步时要特别注意这个配置。
细说行锁
前面在讲行锁时有提到,在 MySQL 的源码中定义了四种类型的行锁,我们这一节将学习这四种锁。
记录锁 Record Locks
记录锁 是最简单的行锁。
1 | UPDATE accounts SET level = 100 WHERE id = 5; |
这条 SQL 语句就会在 id = 5 这条记录上加上记录锁,防止其他事务对 id = 5 这条记录进行修改或删除。记录锁永远都是加在索引上的,就算一个表没有建索引,数据库也会隐式的创建一个索引。如果 WHERE 条件中指定的列是个二级索引,那么记录锁不仅会加在这个二级索引上,还会加在这个二级索引所对应的聚簇索引上(参考上面的加锁流程一节)。
注意,如果 SQL 语句无法使用索引时会走主索引实现全表扫描,这个时候 MySQL 会给整张表的所有数据行加记录锁。如果一个 WHERE 条件无法通过索引快速过滤,存储引擎层面就会将所有记录加锁后返回,再由 MySQL Server 层进行过滤。不过在实际使用过程中,MySQL 做了一些改进,在 MySQL Server 层进行过滤的时候,如果发现不满足,会调用 unlock_row 方法,把不满足条件的记录释放锁(显然这违背了两段锁协议)。这样做,保证了最后只会持有满足条件记录上的锁,但是每条记录的加锁操作还是不能省略的。可见在没有索引时,不仅会消耗大量的锁资源,增加数据库的开销,而且极大的降低了数据库的并发性能,所以说,更新操作一定要记得走索引。
间隙锁 Gap Locks
还是看上面的那个例子,如果 id = 5 这条记录不存在,这个 SQL 语句还会加锁吗?
这个 SQL 语句在 RC 隔离级别不会加任何锁,在 RR 隔离级别为了避免幻读会在 id = 5 前后两个索引之间加上间隙锁。
间隙锁和间隙锁之间是互不冲突的,间隙锁唯一的作用就是为了防止其他事务的插入。
Next-Key Locks
Next-key 锁 是记录锁和间隙锁的组合,它指的是加在某条记录以及这条记录前面间隙上的锁。假设一个索引包含10、11、13 和 20 这几个值,可能的 Next-key 锁如下:
1 | (-∞, 10] |
通常我们都用这种左开右闭区间来表示 Next-key 锁,前面四个都是 Next-key 锁,最后一个为间隙锁。
和间隙锁一样,在 RC 隔离级别下没有 Next-key 锁,只有 RR 隔离级别才有。继续拿上面的 SQL 例子来说,如果 id 不是主键,而是二级索引,且不是唯一索引,那么这个 SQL 在 RR 隔离级别下会加什么锁呢?答案就是 Next-key 锁,如下:
1 | (a, 5] |
其中,a 和 b 是 id = 5 前后两个索引,我们假设 a = 1、b = 10,那么此时如果插入一条 id = 3 的记录将会阻塞住。之所以要把 id = 5 前后的间隙都锁住,仍然是为了解决幻读问题,因为 id 是非唯一索引,所以 id = 5 可能会有多条记录,为了防止再插入一条 id = 5 的记录,必须将下面标记 ^ 的位置都锁住,因为这些位置都可能再插入一条 id = 5 的记录:1 ^ 5 ^ 5 ^ 5 ^ 10 11 13 15
可以看出来,Next-key 锁确实可以避免幻读,但是带来的副作用是连插入 id = 3 这样的记录也被阻塞了。
关于 Next-key 锁,有一个比较有意思的问题,比如下面这个 orders 表(id 为主键,order_id 为二级非唯一索引):
1 | +-----+----------+ |
这个时候不仅 order_id = 5 这条记录会加上 X 记录锁,而且这条记录前后的间隙也会加上锁,加锁位置如下:1 2 ^ 5 ^ 5 ^ 9
可以看到 (2, 9) 这个区间都被锁住了,这个时候如果插入 order_id = 4 或者 order_id = 8 这样的记录肯定会被阻塞,这没什么问题,那么现在问题来了,如果插入一条记录 order_id = 2 或者 order_id = 9 会被阻塞吗?答案是可能阻塞,也可能不阻塞,这取决于插入记录主键的值,感兴趣的可以参考这篇博客。
插入意向锁 Insert Intention Locks
插入意向锁 是一种特殊的间隙锁(所以有的地方把它简写成 II GAP),这个锁表示插入的意向,只有在 INSERT 的时候才会有这个锁。注意,这个锁虽然也叫意向锁,但是和上面介绍的表级意向锁是两个完全不同的概念,不要搞混淆了。插入意向锁和插入意向锁之间互不冲突,所以可以在同一个间隙中有多个事务同时插入不同索引的记录。譬如在上面的例子中,id = 1 和 id = 5 之间如果有两个事务要同时分别插入 id = 2 和 id = 3 是没问题的,虽然两个事务都会在 id = 1 和 id = 5 之间加上插入意向锁,但是不会冲突。
插入意向锁只会和间隙锁或 Next-key 锁冲突,正如上面所说,间隙锁唯一的作用就是防止其他事务插入记录造成幻读,那么间隙锁是如何防止幻读的呢?正是由于在执行 INSERT 语句时需要加插入意向锁,而插入意向锁和间隙锁冲突,从而阻止了插入操作的执行。
行锁的兼容矩阵
下面我们对这四种行锁做一个总结,它们之间的兼容矩阵如下图所示: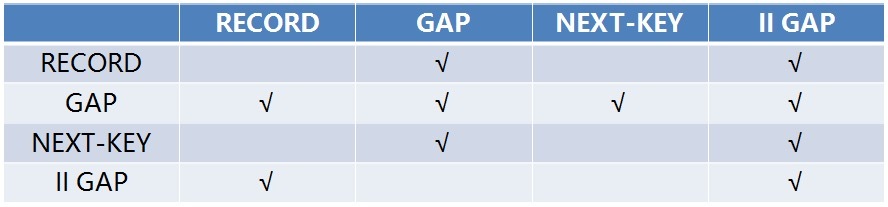
其中,行表示已有的锁,列表示要加的锁。