了解分布式一致性的一些概念和理论,介绍简单常用的分布式一致性协议。主要介绍二阶段提交和三阶段提交的基本流程,并相互比较。

分布式的特点
- 分布性:系统中的机器随意分布。
- 对等性:组成分布式系统的所有节点都是对等的。
- 并发性:需要协调并发操作一些共享资源。
- 缺乏全局时钟:在分布式系统中,很难定义两件事情谁先谁后。
- 故障总是会发生:任何在设计阶段考虑到的异常情况,一定会在系统实际运行中发生。
分布式系统常见问题
- 通讯异常:单机内存访问往往延时在纳秒数量级(通常是 10ns 左右);网络则在 0.1~1ms,消息丢失和消息延迟变得非常普遍
- 网络分区:俗称”脑裂”,部分节点和整个分布式系统失去联系,自己单独组成了一个小集群。
- 三态:成功、失败和超时。无法预测超时的请求是否到达了接收方,还是在接收方返回的时候丢失了。
CAP 和 BASE 理论
通常可以把一系列的分布式的操作序列称之为子事务。分布式事务也可以被定义为一种嵌套型事物。分布式系统不可能像单机系统那样可以严格满足 ACID 特性,所以要有不同的取舍,因此有了 CAP 和 BASE 理论。
CAP
一个分布式系统不可能同时满足一致性(C:Consistency)、可用性(A:Availability)和分区容错性(P:Partition tolerance)这三个基本需求。
一致性: 在分布式环境中,一致性是指数据在多个副本之间是否能够保持一致的特性。数据在发生变化的时候,需要保证发生变化之后,所有的副本都能保持一致。
可用性:系统提供的服务必须一直处于可运送的状态,对于每一个请求总是能够在有限的时间内返回结果。
分区容错性: 分布式系统在遇到任何网络分区故障的时候,仍然需要保证对外提供满足一致性和可用性的服务。

对于 CAP 的取舍:放弃 P 的通用做法是将所有的数据都放到一个节点,这样可以避免网络分区带来的问题,但是值得注意的是,放弃了 P 也就等于放弃了系统的扩展性;放弃 A :当系统发生故障的时候,允许系统短时间内不可用,需要等待系统恢复后方可继续提供服务; 放弃 C:放弃 C 并不是说放弃最终一致性,而是说放弃强一致性,保证系统在某段时间之后能够达到最终一致性。
对于一个分布式系统而言,不同节点之间必然存在网络通讯,因此网络分区问题是不可避免的。同时分布式系统的扩展特性也是无法舍弃的。因此系统的设计和架构一般都考虑如何权衡 A 和 C。
BASE
BASE 是 Basically Available(基本可用)、Soft status(软状态)和 Eventually consistent(最终一致性)三个短语的缩写。
基本可用:在系统出现故障的时候,允许损失部分可用性。比如响应时间上的损失和功能上的损失。
软状态: 也称为弱状态,表示允许系统中的数据存在中间状态,即允许不同的数据副本之间数据同步存在延迟。
最终一致性: 经过一段时间的同步之后,系统最终能够达到一个数据一致的状态。
最终一致性的一些变种:
- 因果一致性:进程 A 更新数据后通知了进程 B,进程 B 必须对修改后的数据可见。
- 读己之所写:进程 A 对数据做的更改,自己总是能够获得最新的值。
- 会话一致性:在单个会话中,进程 A 总是能够看到最新的值。
- 单调读一致性:在系统中读出数据项 Y 的值 y 后,后面的读取中不允许返回比 y 更旧的值。
- 单调写一致性:系统需要保证来自同一个进程的写操作被顺序的执行。
2PC 与 3PC
2PC 和 3PC 就是用来保证 CAP 中的 C 或者 BASE 里面的 E 的协议。
当一个事务需要跨越多个分布式节点的时候,需要引入一个成为**”协调者”(Coordinator)的组件来统一调度所有分布式节点的执行逻辑,这些被调度的分布式节点则被称为“参与者”(Participant)**。协调者负责调度参与者的行为,并最终决定这些参与者是否真的需要把事务进行真正的提交。由此,衍生出二阶段提交和三阶段提交两种协议。
2PC
两阶段提交主要包含投票(Propose)和执行(Commit)两个阶段。
在 Propose 阶段,协调者向所有参与者(voter)发送事务内容,询问是否可以执行事务提交操作,并等待参与者的响应。各个参与者为该事务预留资源,保证在下一个阶段能够提交事务,如果资源可以获取反馈给协调者 agree 响应,反之返回 disagree 响应。
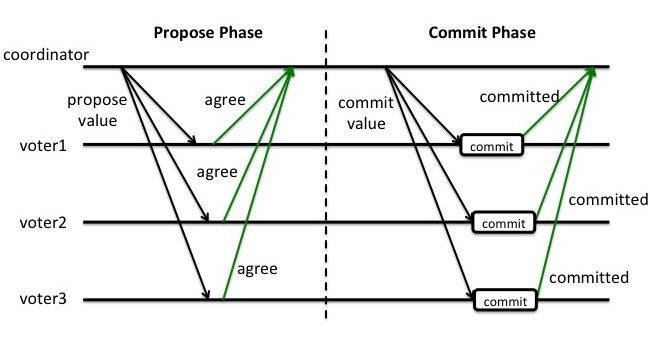
事务提交:如果在 Propose 阶段,所有参与者都返回的是 agree 信号,那么协调者会发送提交事务的请求;所有参与者收到事务提交请求后会正式执行事务提交操作并释放事务执行期间占用的资源,执行完成后将事务执行结果反馈给协调者;协调者收到所有参与者的反馈信息后,事务执行完毕。
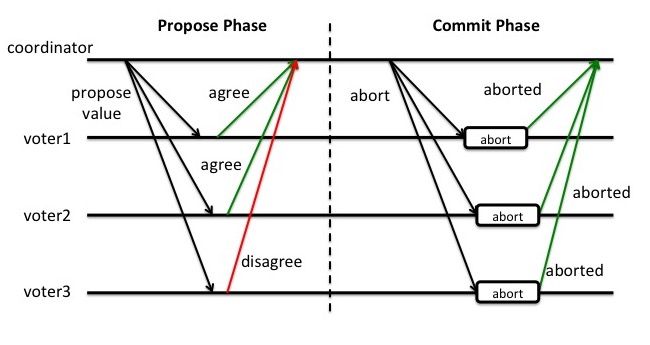
事务中断: 如果在 Propose 阶段有参与者返回 disagree 或者有的节点超时未返回,没有投票达成一致,那么协调者会向所有参与者发送回滚请求;参与者收到回滚请求之后会释放掉在 Propose 阶段占用的资源,然后反馈信号给协调者;协调者收到反馈消息之后,完成事务终端。
二阶段提交协议的优点是:原理简单,实现方便。
二阶段提交协议的缺点是:
- 同步阻塞:2PC 协议的各个阶段都是同步阻塞的,任何节点故障都有会导致事务提交失败。
- 单点问题:一旦协调者出现问题,将无法提交事务。如果协调者在收到参与者的 Propose 确认之后,发送 Commit 信号之前发生故障,那么所有参与者占用的资源将无法得到释放。
- 数据不一致:如果在 Commit 阶段部分参与者发生了故障,导致事务无法提交,但是正常的参与者提交了事务。导致数据不一致。
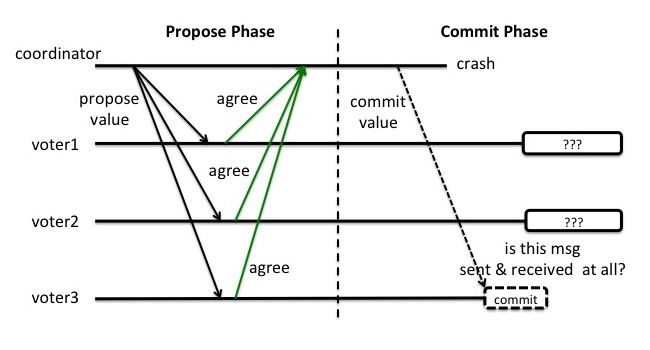
假设coordinator和voter3都在Commit这个阶段crash了, 而voter1和voter2没有收到commit消息. 这时候voter1和voter2就陷入了一个困境. 因为他们并不能判断现在是两个场景中的哪一种:
- 上轮全票通过然后 voter3 第一个收到了 commit 的消息并在 commit 操作之后 crash 了。
- 上轮 voter3 反对所以干脆没有通过。
3PC
三阶段提交是在二阶段提交的基础上进行的改进,将二阶段提交的 Propose Phase 一分为二,形成了 CanCommit、PreCommit 和 doCommit 三个阶段。
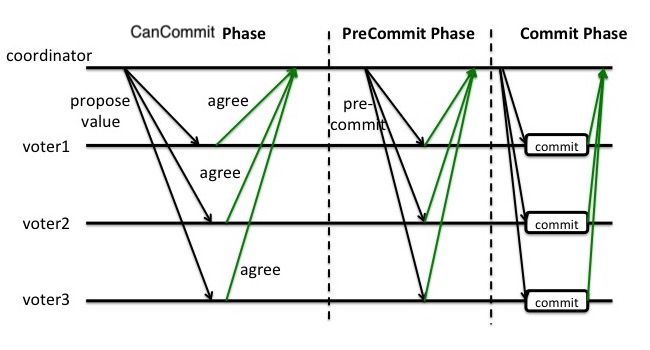
CanCommit:协调者向所有参与者询问是否可以执行事务提交操作;各参与者想协调者反馈是否可以提交事务。
PreCommit:
- 如果所有参与者反馈的都是 agree, 那么就会执行事务预提交。协调者发送 PreCommit 请求,参与者收到请求之后进行资源的分配工作,最后将资源分配结果反馈这协调者。等待后面的 commit 命令或者 abort 命令。
- 如果任意一个参与者返回了 disagree,或者在协调者等待超时之后。协调者将会向所有参与者节点发送 abort 请求。
doCommit:
- 如果上面 PreCommit 全部成功,即协调者收到了全部参与者的成功反馈,那么协调者将会发送 doCommit 请求;参与者接收到 doCommit 会正式提交事务然后释放事务执行期间占用的资源,反馈事务提交结果给协调者;协调者收到参与者反馈的消息后,完成事务。
- 如果上面的 PreCommit 有部分失败反馈,或者是等待超时就会中断事务。协调者会向所有参与者节点发送 abort 请求;参与者收到 abort 请求后执行回滚操作,并反馈给协调者;协调者收到反馈消息后,完成事务的中断。
需要注意的是,在 doCommit 阶段,可能出现下面的两种故障:
- 协调者出现问题
- 协调者和参与者之间网络故障
无论出现上面那种情况,都会造成从黁税额无法及时收到来自协调者的 doCommit 请求或者是 abort 请求,针对这种情况,参与者会在等待超时之后,继续事务的提交操作。
三阶段提交协议的优点是:相比于 2PC 能够在单点故障后继续达成一致。
三阶段提交协议的缺点是:引入了新的问题,如果某个参与者与协调者出现在不同的网络分区,那么该参与者会提交事务,有可能出现数据不一致的情况。